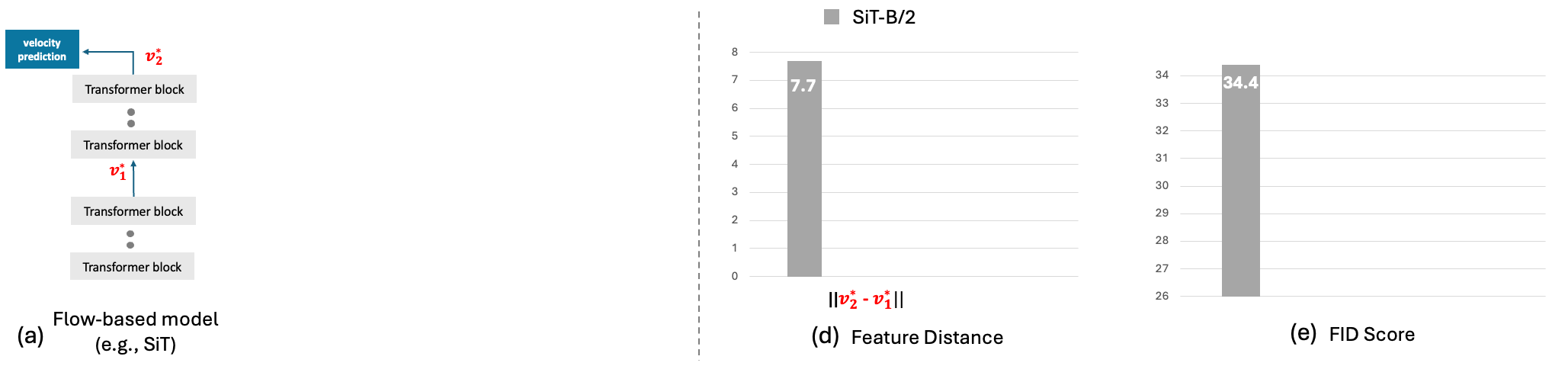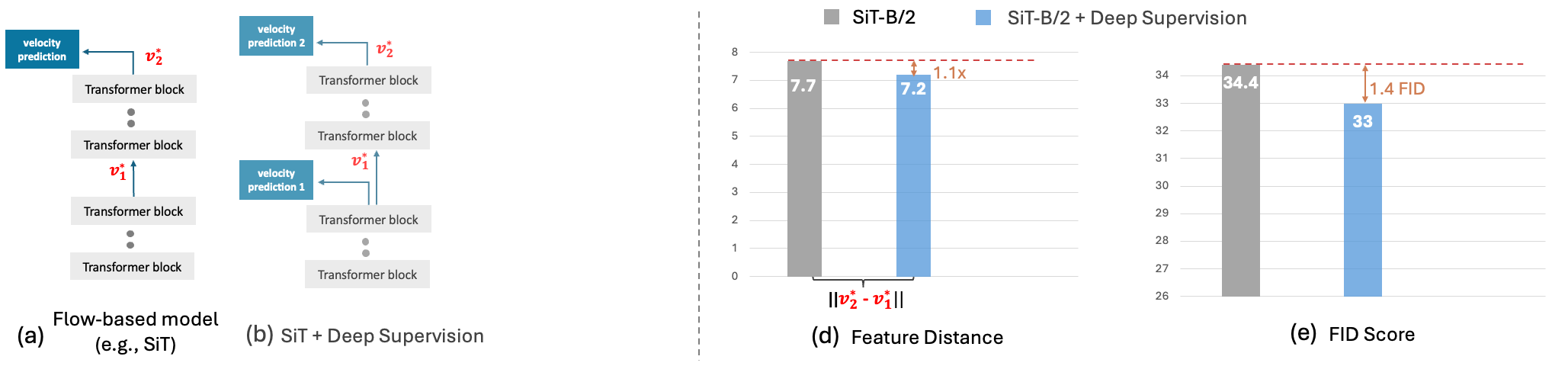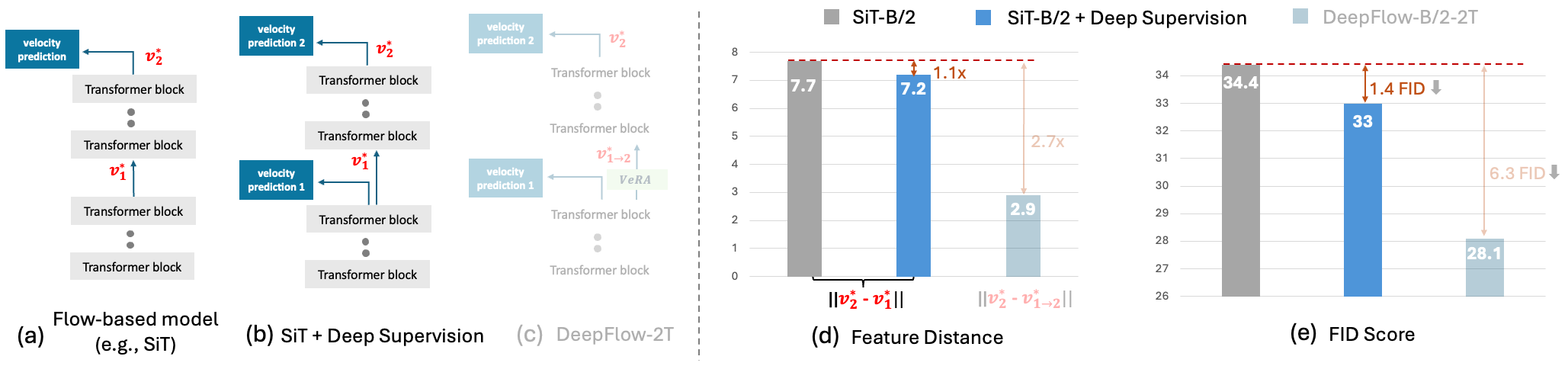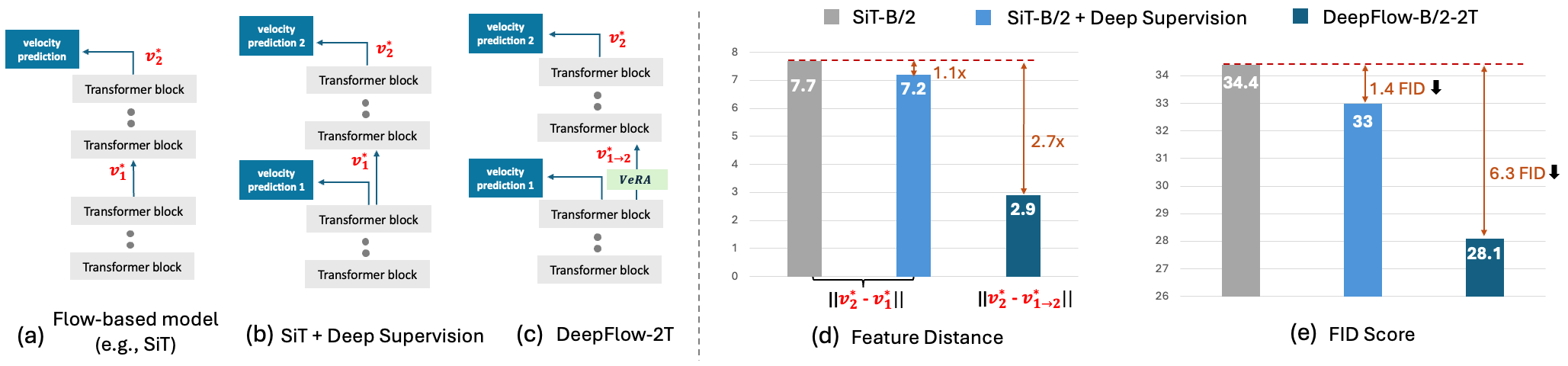
Flow-based generative models have charted an impressive path across multiple visual
generation tasks by adhering to a simple principle: learning velocity representations
of a linear interpolant. However, we observe that training velocity solely from the
final layer’s output under-utilizes the rich inter-layer representations, potentially
impeding model convergence. To address this limitation, we introduce DeepFlow, a novel framework
that enhances velocity representation through inter-layer communication.
DeepFlow partitions transformer layers into balanced branches with deep supervision
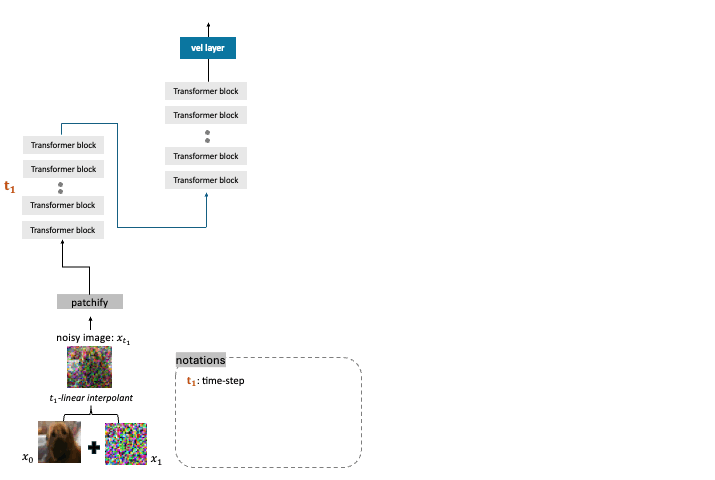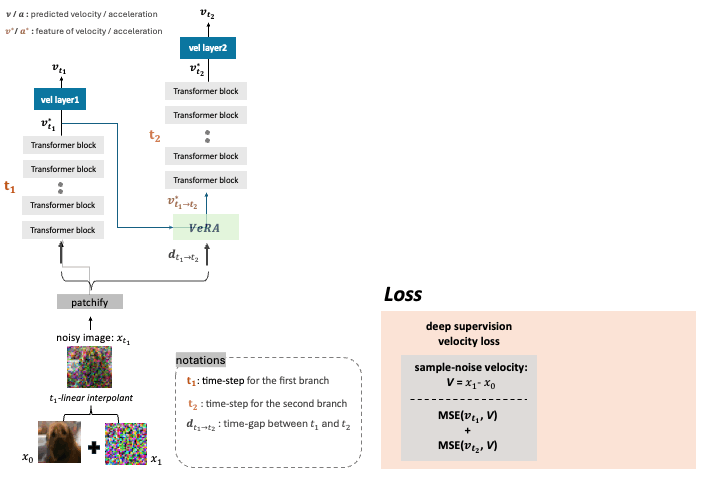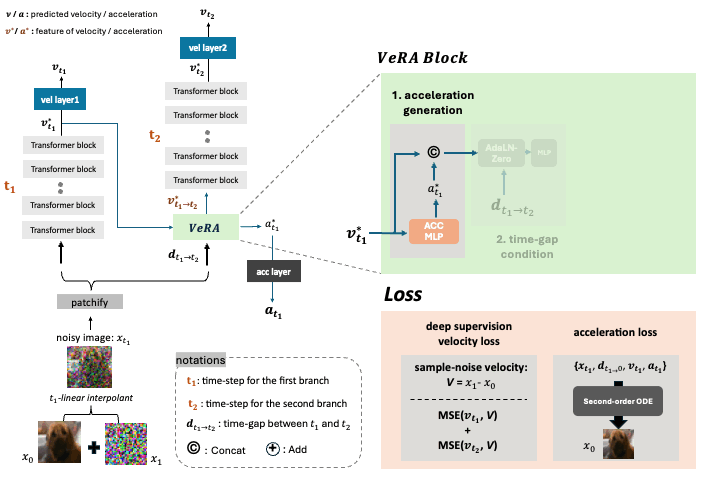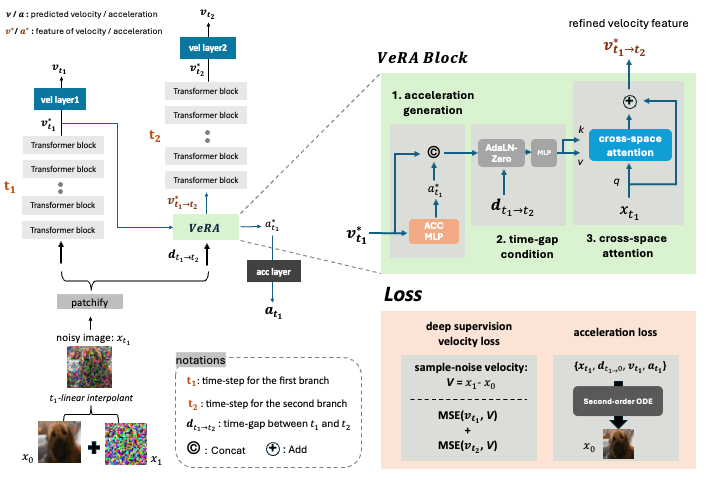
and inserts a lightweight Velocity Refiner with Acceleration (VeRA) block between
adjacent branches, which aligns the intermediate velocity features within transformer blocks.
Powered by the improved deep supervision via the internal velocity alignment,
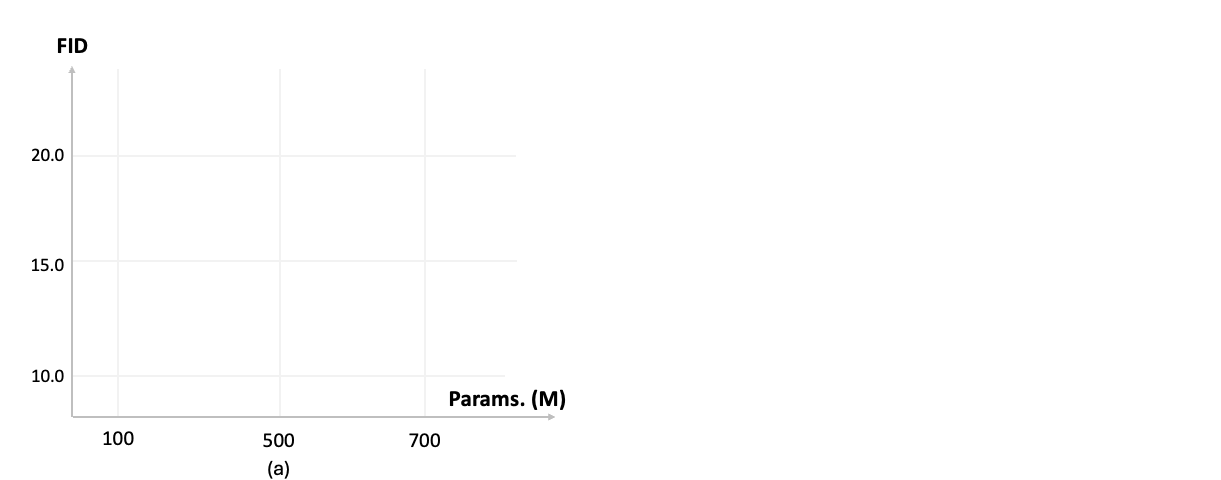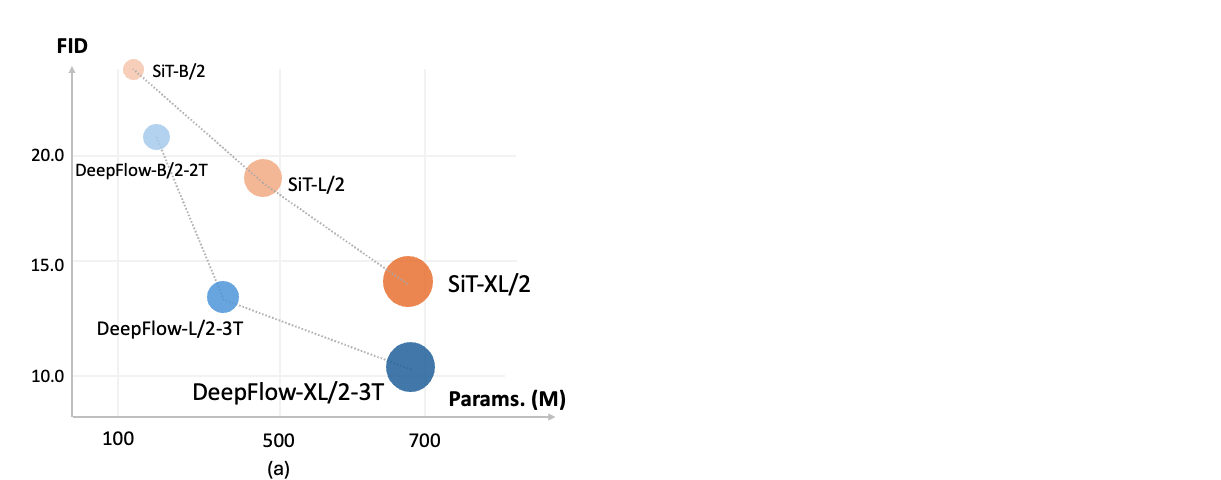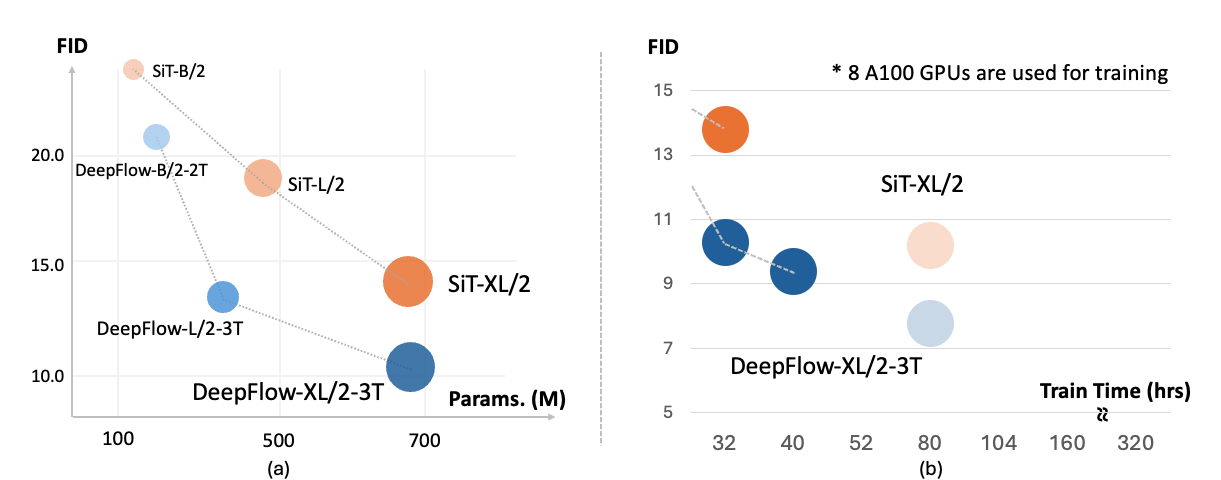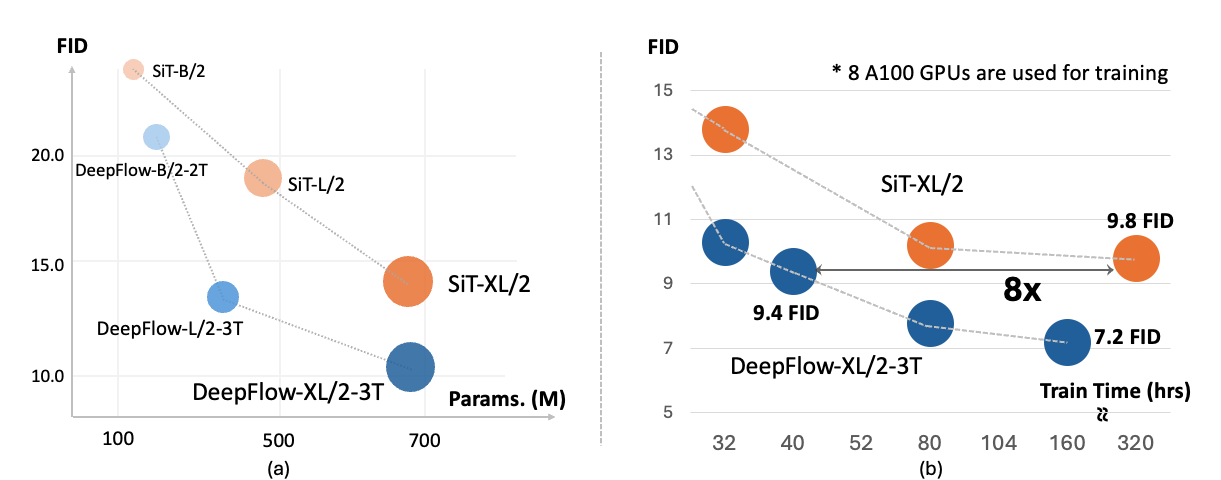
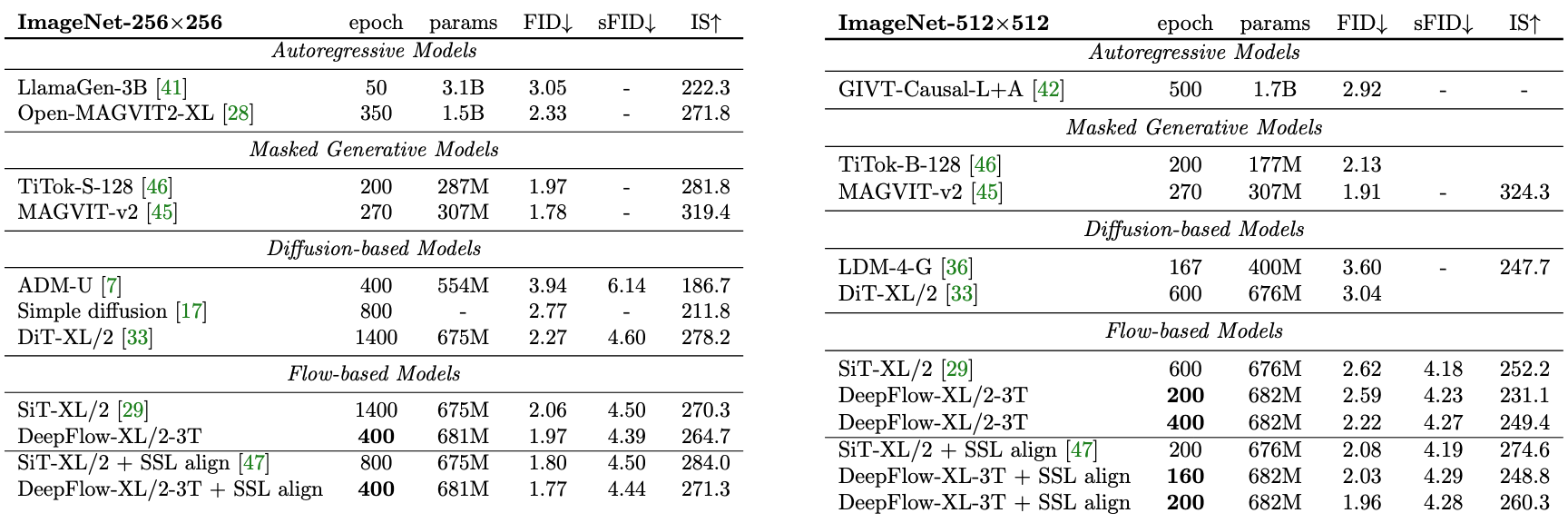
DeepFlow converges 8x faster on ImageNet-256x256 with equivalent performance.